Theo làn sóng của các kiến trúc microservice, Event Driven Architecture – EDA – Kiến trúc Hướng Sự kiện ngày càng trở nên phổ biến. Sự uyển chuyển của EDA – tới từ một cấu trúc xoay quanh khái niệm Sự kiện – mang lại cho sản phẩm khả năng tổ chức các dịch vụ khác nhau một cách bất đồng bộ và ít phụ thuộc nhau về mặt tổng thể. Khối lượng và sự đa dạng của các quá trình xử lý dữ liệu – vấn đề cố hữu của kiến trúc microservice – đã khiến EDA trở thành ứng viên sáng giá cho nhiều nền tảng. Bài đăng này sẽ vén màn điều đó.
Từ monoliths tới Bounded Contexts với REST APIs
Nghành phần mềm đã quen thuộc với những dịch vụ lớn được thiết kế xoay quanh một cơ sở dữ liệu trung tâm trong rất nhiều năm. Trước khi chúng ta có docker container và đám mây, việc vận hành một tập tiến trình hình thức lớn là rất khó khăn. Bởi vậy mà thường thì chỉ có một tiến trình nguyên khối duy nhất được triển khai trên một tập lớn các máy chủ. Còn CSDL được quản lý tập trung, tại vị trí trung tâm, trên một máy chủ mạnh, để tận dụng tối đa sức mạnh của các hệ quản trị CSDL.
Theo thời gian, các nhóm sản xuất cũng như các phần mềm trở nên lớn và phức tạp hơn. Hầu hết chuyển sang hệ thức Agile của sự tích hợp liên tục và triển khai liên tục. Với sự dịch chuyển này, tiến trình nguyên khối (monolyith) bắt đầu được phân rã thành các phạm vi ngữ cảnh (Bounded Context) khác nhau – nơi chúng được quản lý bởi các nhóm khác nhau. Điều này cho phép cắt đứt sự phụ thuộc giữa hoạt động phát triển và triển khai.
Chuyển đổi này đưa chúng ra rời khỏi việc xây dựng các ứng dụng lớn một cách đơn lẻ và thay vào đó hướng tới xây dựng một nền tảng của những ứng dụng độc lập, mà tất cả hoạt động cùng nhau để hướng tới mục tiêu giải quyết được những gì mà các hoạt động nghiệp vụ cần đến. Các cấu phần đó cần giao tiếp với nhau, và REST APIs là một cách phổ biến để thực hiện điều này. Với kiến trúc này, các phạm vi ngữ cảnh chịu trách nhiệm hoàn toàn về dữ liệu của chúng. Mỗi phạm vi không có quyền truy cập tới CSDL của phạm vi khác, mọi truy cập đều phải thông qua những APIs được công bố.
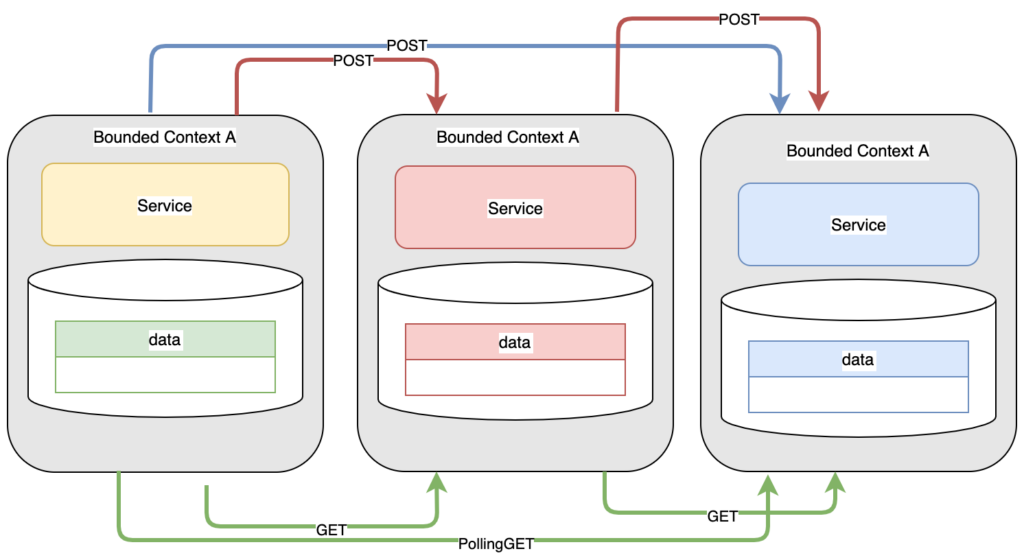
Thiết kế này cho phép đập vỡ monolith, nhưng nó cũng tạo ra các thách thức khác:
- Các dịch vụ nội bộ – đại diện cho các nghiệp vụ nội bộ – thường cần đến các APIs nâng cao (chẳng hạn khóa tài khoản) – thứ không được cho phép khách hàng cuối tiếp xúc tới. Việc gộp những khả năng này vào cùng một phạm vi với các dịch vụ khác (hoạt động trên cùng một nguồn dữ liệu) sẽ làm tăng đáng kể độ phức tạp của mã nguồn cũng như chi phí phát triển và bảo trì. Nhưng khi tách biệt ngữ cảnh ra, việc tách rời CSDL sẽ khiến các dịch vụ nội bộ phát sinh thêm nhu cầu thăm dò sự thay đổi trên nguồn dữ liệu có chung ngữ cảnh. Ví dụ: khi có một khách hành thay đổi email (phạm vi công cộng), các dịch vụ nội bộ sẽ không thể biết được điều đó cho tới khi chúng thực hiện hoạt động thăm dò.
- Các điểm đầu cuối dành riêng cho giao tiếp nội bộ giữa các dịch vụ sẽ có các yêu cầu bảo mật và phương thức xác thực/phân quyền khác, và thường là phức tạp hơn – so với những gì dành cho người dùng.
- Trong trường hợp các phạm vi bị phụ thuộc vào nhau – chẳng hạn một dịch vụ cần tới một dịch vụ khác, các vấn đề về độ trễ và độ sẵn sàng sẽ phát sinh. Một chuỗi các sự phụ thuộc sẽ phát sinh vấn đề lớn về độ trễ, và bất kỳ dịch vụ nào trong chuỗi gặp sự cố sẽ phát sinh vấn đề về availability. Và quản lý sự đứt đoạn đó sẽ phát sinh vấn đề lớn về sự phức tạp của mã nguồn – trên tất cả các dịch vụ trong chuỗi.
- Bất kỳ dịch vụ nào được dịch vụ khác phụ thuộc tới cũng sẽ phát sinh nhu cầu mở rộng quy mô để có thể đảm bảo performance và availability. Chẳng hạn khi có nhiều dịch vụ khác nhau cùng hoạt động xoay quanh một dịch vụ trung tâm, độ trễ trong bất kỳ dịch vụ nào tham gia vào mạng lưới cũng sẽ được đồng bộ lên hoạt động của tất cả các dịch vụ khác và gây ra sự tụt giảm hiệu năng nghiêm trọng.
Kiến trúc Hướng Sự kiện
Các thách thức trên dẫn chúng ta tới với Kiến trúc Hướng Sự kiện. Chúng ta có thể định nghĩa nó là một kiến trúc mà trong đó các dịch vụ độc lập giao tiếp một cách gián tiếp với nhau, một cách bất đồng bộ, bằng cách xuất bản và sử dụng dữ liệu tới/từ các hàng đợi.
Khi một sự kiện xảy ra trong một phạm vi ngữ cảnh (ví dụ người dùng thay đổi email, khách hàng đưa thứ gì đó vào giỏ hàng, đơn hàng được đặt, lượng sản phẩm tồn kho thay đổi…), thông tin về những sự kiện đó sẽ được xuất bản vào hàng đợi. Các dịch vụ trong một phạm vi ngữ cảnh khác mà có mối quan tâm tới các sự kiện đó có thể đăng ký tới hàng đợi liên quan và nhận thông tin về sự kiện, để xử lý khi cần thiết.
Một trong những lợi thế lớn nhất của kiến trúc này là khả năng cắt đứt sự phụ thuộc, mà theo đó:
- Các dịch vụ sẽ không còn cần phải biết tới sự tồn tại của nhau
- Các dịch vụ có thể gặp lỗi mà không gây ra ảnh hưởng dây chuyền
- Các dịch vụ có thể được mở rộng một cách độc lập, độ trễ tại một dịch vụ không gây ra độ trễ cộng gộp ở dịch vụ khác
- Các dịch vụ có thể được phát triển bằng các ngôn ngữ và công nghệ thích hợp, miễn là chúng có khả năng tương tác được với công nghệ dùng cho các hàng đợi
Một ứng dụng mẫu
Ví dụ sau đây dựa trên một mô hình ứng dụng mua sắm đơn giản.
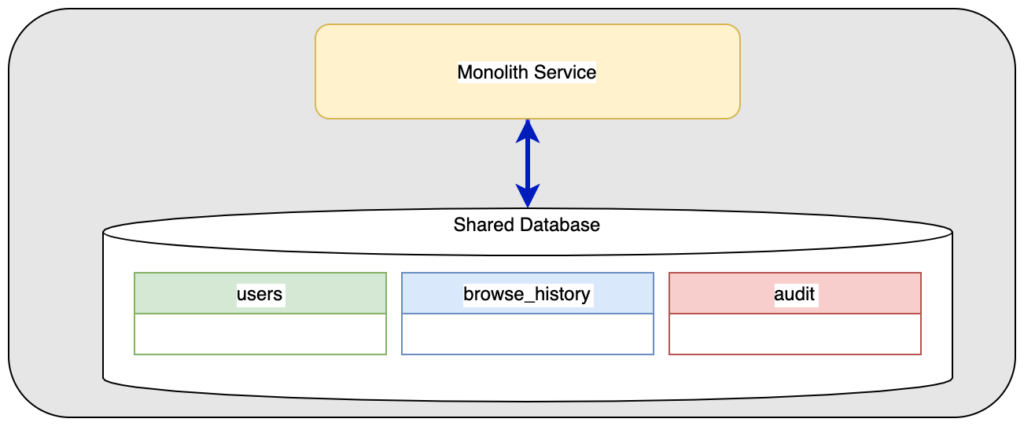
Ứng dụng monolith ban đầu
Ứng dụng monolith nguyên thủy có một dịch vụ với các bảng nằm trong một cơ sử dữ liệu trung tâm. Có ba khối dữ liệu sẽ được mang ra thảo luận ở đây:
- Dữ liệu thông tin người dùng
- Dữ liệu lịch sử duyệt sản phẩm
- Dữ liệu đặt lệnh của người dùng, dùng cho mục đích kiểm toán
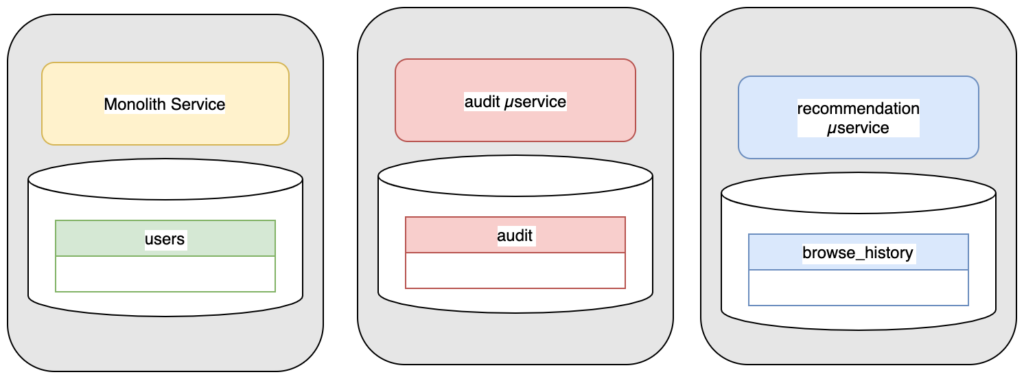
Microservice và các REST API
Khi nghiệp vụ kinh doanh mở rộng và phát triển, dịch vụ nguyên thủy được chia thành ba phạm vi ngữ cảnh độc lập với nhau. Hầu hết các tính năng của sản phẩm vẫn sẽ được giữ lại trong khối monolith, trong khi đó các nghiệp vụ giới thiệu sản phẩm và kê sổ được thiết kế, phát triển, duy trì và vận hành bởi các nhóm khác. Mỗi nhóm sẽ khả năng điều chỉnh quy mô, nhu cầu hiệu suất và kiến trúc dữ liệu một cách độc lập.
Bước đi này sẽ kéo theo một số thao tác cần phải thực hiện, để khối monolith có thể lấy thông tin từ dịch vụ giới thiệu sản phẩm và dịch vụ kê sổ.
Phương cách phổ biến là mở các REST API trên các dịch vụ mới, và theo đó khối monolith sẽ kết nối và POST các sự kiện khi chúng xảy ra.
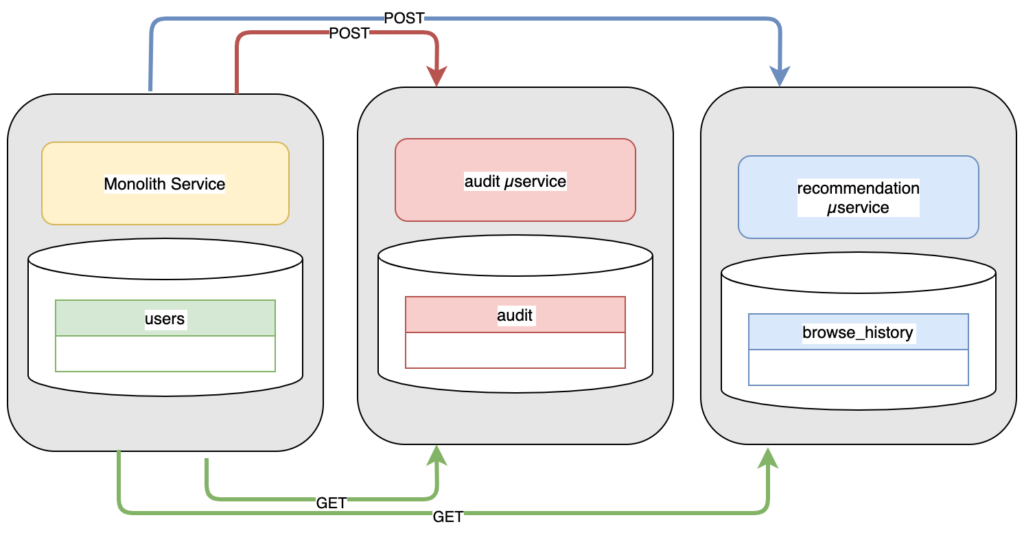
Và kéo theo một số vấn đề kỹ thuật:
- Độ trễ cộng gộp
- Đoản mạch trong chuỗi đồng bộ
- Sự phụ thuộc nhau rất chặt chẽ về mặt hợp đồng giữa các API
- Tất cả các dịch vụ đều phải mở rộng một cách bắt buộc để đồng bộ với các tình huống lưu lượng truy cập lớn xảy ra trên khối monolith
- Bản thân mỗi API không quá phức tạp, nhưng chúng có thể kéo theo các thao tác liên quan làm tăng chi phí phát triển và độ phức tạp của mã nguồn một cách nhanh chóng. Một API UPDATE đơn giản có thể kéo theo rất nhiều API GET, PUT, POST, valitadation, authentication… liên quan.
Kiến trúc Hướng Sự kiện với API Ba Bên
Khi chuyển sang kiến trúc với ba bên API:
- Một giao diện REST cho các dịch vụ công cộng, tường minh phục vụ các request đồng bộ
- Một giao diện để xuất bản các sự kiện phát sinh vào hàng đợi, để các dịch vụ có thể đăng thông tin về những sự kiện mà các dịch vụ khác có thể quan tâm
- Một giao diện dành cho tiêu thụ sự kiện, để các phạm vi bị ràng buộc có thể đọc thông tin về sự kiện từ hàng đợi
- Các phạm vi bị ràng buộc đọc thông tin về sự kiện thông qua một cấu phần phụ, nơi chúng liên tục lưu trữ và chia sẻ dữ liệu.
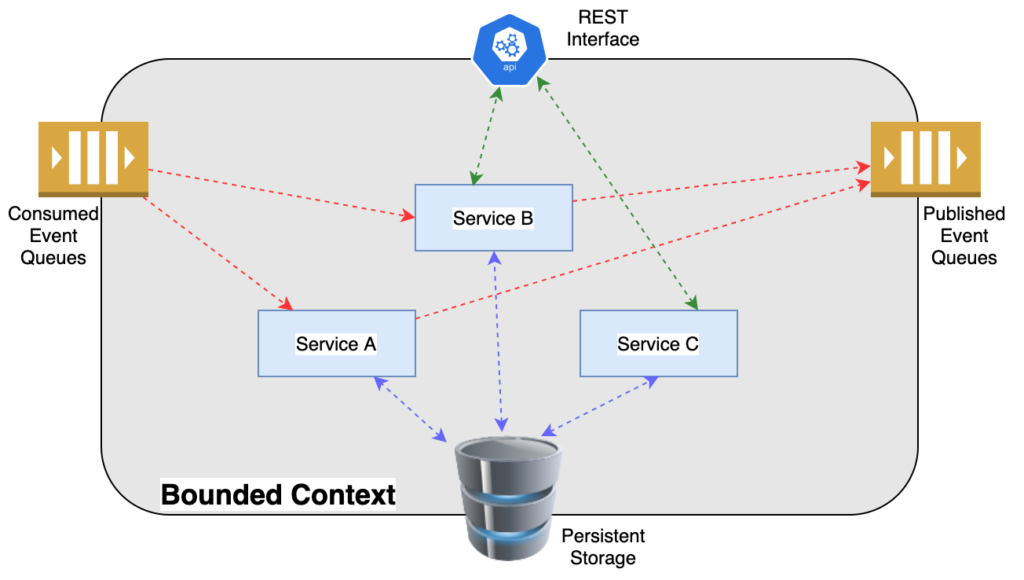
Kiến trúc này giải quyết nhiều thay đổi về mặt thiết kế mà chúng ta đã thấy trước đó:
- Không – hoặc ít nhất là có tối thiểu các điểm API đầu cuối dành cho giao tiếp nội bộ cần được tạo. Hầu hết các API là dành cho các dịch vụ nằm ở tầng ngoại vi – thứ không nắm dữ liệu riêng, và do đó không có khả năng tiêu thụ dữ liệu từ hàng đợi (chẳng hạn như các dịch vụ dành cho giao diện React). Các dịch vụ tại ngữ cảnh ngoại vi vẫn cần thiết phải xuất bản các sự kiện xảy ra trong phạm vi của chúng, nhưng chúng không cần thiết phải ra lệnh và điều khiển các API dành cho giao tiếp với các dịch vụ khác, các mối giao tiếp đó được thực hiện gián tiếp thông qua các API tiêu thụ sự kiện.
- Xác thực và phân quyền khả năng truy cập cho các giao tiếp từ dịch vụ tới dịch vụ có thể được điều khiển tại dịch vụ xuất bản/tiêu thụ, hoàn toàn không phụ thuộc với việc điều khiển xác thực/phân quyền cho giao tiếp giữa người dùng với dịch vụ.
- Không tồn tại độ trễ cộng dồn, không tồn tại sự phụ thuộc về availability, do các giao tiếp dịch vụ/dịch vụ là bất đồng bộ. Nếu dịch vụ xuất bản bị sập hay bị chậm, các dịch vụ đang quan tâm tới nó sẽ đơn giản là không nhận được thông tin, nếu dịch vụ tiêu thụ bị sập hay bị chậm, các sự kiện đơn giản là vẫn nằm lại trong hàng đợi.
- Các dịch vụ lắng nghe và tiêu thụ trong các phạm vi ngữ cảnh có thể được scale dựa theo tốc độ xử lý của chúng tại trạng thái ổn định. Nếu có nhảy vọt về lưu lượng truy cập, các event về cơ bản là được lưu đệm trong hàng đợi và sau đó hoàn toàn có thể xử lý tuần tự.
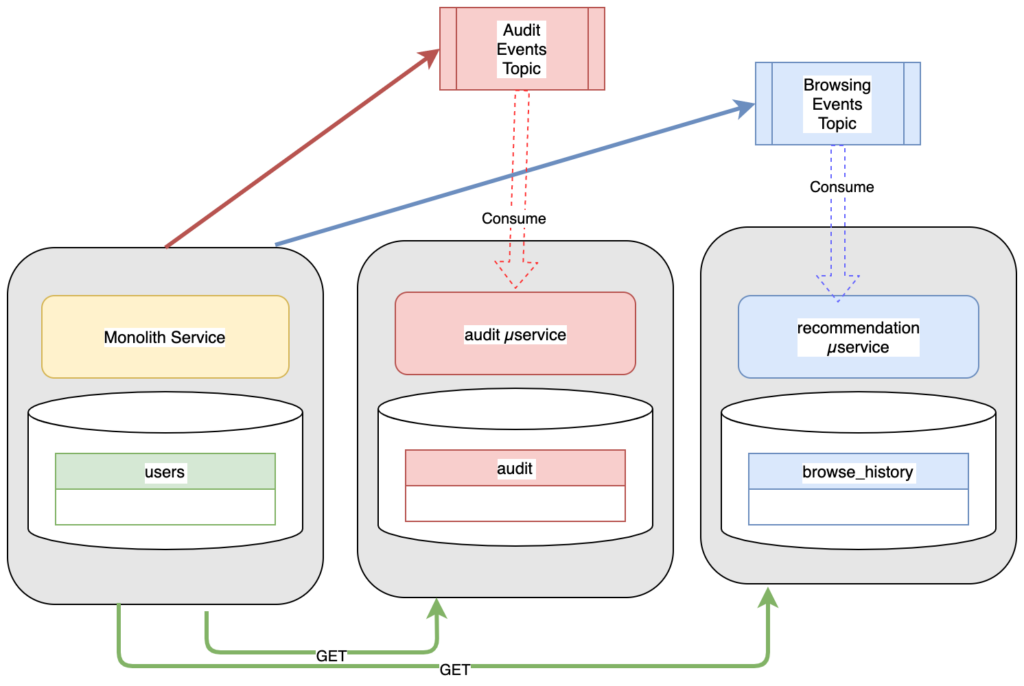
Như vậy, sẽ có một số cập nhật trên thiết kế:
- Khối monolith xuất bản các sự kiện thanh toán tới hàng đợi Thanh toán.
- Khối monolith xuất bản các sự kiện duyệt sản phẩm tới hàng đợi Duyệt sản phẩm.
- Dịch vụ kê sổ lắng nghe và tiêu thụ các sự kiện từ hàng đợi thanh toán, lọc ra các thông tin quan trọng và lưu trữ những thông tin đó vào CSDL của mình. Với nhiệm vụ đó, dịch vụ kê sổ có thể được scale lại rất nhỏ, rất ít nhu cầu tính toán xảy ra tại đây, và rất ít nhu cầu về hiệu năng cao hay độ trễ thấp.
- Dịch vụ giới thiệu sản phẩm lắng nghe và tiêu thụ sự kiện từ hàng đợi Duyệt, lọc ra các thông tin quan trọng và từ đó cập nhật các sản phẩm trong danh mục khuyến khích mua của người dùng. Dịch vụ này có thể được scale lớn tùy ý, tùy theo độ phức tạp của các phép tính toán và hiệu năng mà nghiệp vụ kinh doanh mong muốn.
Triển khai với Kafka và RabbitMQ
Có hai lựa chọn phổ biến để triển khai thiết kế về hàng đợi, Apache Kafka và RabbitMQ. Cả hai đều mạnh mẽ, hoàn thiện, được duy trì/bảo trì tốt với sự hỗ trợ sâu rộng từ các nhà cung cấp dịch vụ đám mây và nghành công nghiệp. Còn nhiều hệ thống khác với các mục đích thiết kế chuyên biệt khác nữa nhưng sẽ không được đề cập tới ở đây. Cả Kafka và RabbitMQ đều khá phức tạp và mang nhiều khía cạnh. Trước khi bất kỳ hệ thống nào được lựa chọn, việc nghiên cứu và kiểm nghiệm nên được tiến hành, để có thể ra được quyết định lựa chọn dựa theo những gì mà nghiệp vụ kinh doanh cũng như nghiệp vụ kỹ thuật cần tới.
Xuất bản và tiêu thụ
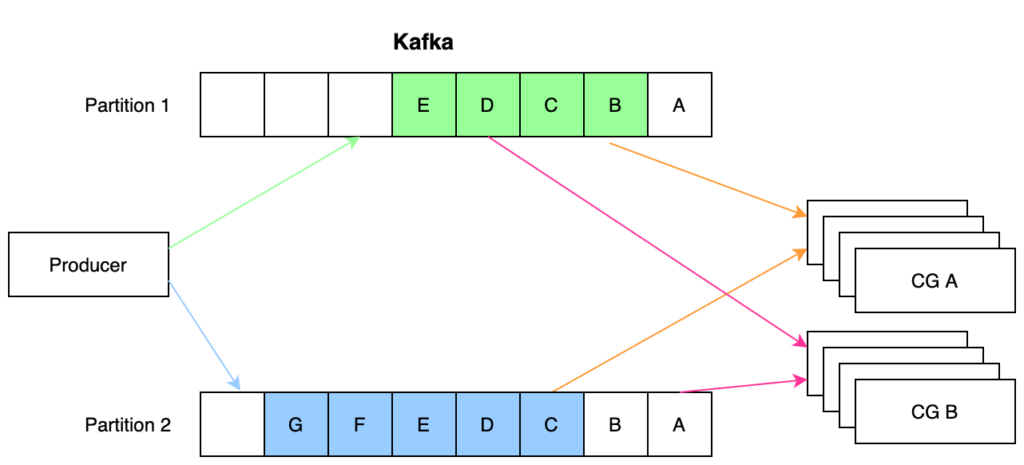
Cả Kafka và RabbitMQ đều có các producer (dịch vụ xuất bản) và consumer (dịch vụ tiêu thụ). Dữ liệu lưu phía trong được Kafka gọi là Topic, và RabbitMQ gọi là Queue. Trong ví dụ dưới đây, 7 sự kiện (A tới G) đã được sản xuất và đưa vào hàng đợi, sự kiện A đã được tiêu thụ, và sự kiện B đang sẵn sàng để tiêu thụ tiếp sau. Trong cả Kafka và RabbitMQ, vị trí B này được theo dõi chặt chẽ, khi một consumer thất bại trong việc tiêu thụ một event, hay bị sập và được khởi động lại, việc tiêu thụ vẫn sẽ bắt đầu lại từ vị trí B, bởi hệ thống đã ghi nhận vị trí đó.

Bên trong Kafka
Kafka Producer ghi các sự kiện vào các topic, các topic thì được phân tách thành nhiều partition, mỗi partition được lưu trữ tại một Broker. Có tối thiểu 3 Broker trên một Kafka cluster, và Kafka có thể được mở rộng bằng cách tăng số lượng broker (theo đó tăng số lượng partition tối đa có thể chia). Ví dụ, đặt hệ số nhân bản broker là 2, thì với 6 Broker ta có thể có tối đa 3 phân vùng cho mỗi Topic.
Các consumer đăng ký theo dõi event với cluster và dưới danh nghĩa một Consumer Group (CG). Trong ví dụ dưới đây, nhóm CG A đã tiêu thụ tới event A trong partition 1 và event B trong partition 2. Nhóm CG B đã tiêu thụ tới C trên partition 1 và chỉ đang sẵn sàng để tiêu thụ event A trên partition 2. Mỗi event chỉ nằm trên một partition duy nhất, và mỗi partition thì được đảm bảo xử lý FIFO, theo đó mỗi event chỉ được mỗi CG tiêu thụ một lần duy nhất. Nếu có nhiều partition, các event sẽ được rải xoay vòng vào các partition khác nhau, hoặc lựa chọn partition một cách có chủ đích. Event đã được tiêu thụ sẽ được nằm trên topic một thời gian nữa, tùy theo cấu hình, mặc định 7 ngày.
Mỗi CG có thể có nhiều consumer thành viên (thường là các container replica của cùng một dịch vụ), mỗi thành viên được chỉ định sở hữu một partition, mỗi partition chỉ được sở hữu bởi một thành viên trong một thời điểm. Với 2 partition trong ví dụ dưới đây, bất kỳ thành viên nào kể từ thứ 3 trở đi sẽ không có partition nào để theo dõi và tiêu thụ event.
Bên trong RabbitMQ
Với RabbitMQ, một producer xuất bản event thông qua một Exchange. Exchange có nhiệm vụ lọc event thông qua một số luật logic và sau đó phân bổ vào các queue. Một tập hợp các consumer kết nối tới một queue và xóa bỏ event khỏi queue sau khi đã tiêu thụ xong. Các consumer trong một tập cạnh tranh với nhau – bất kỳ container nào hoàn thành công việc tiêu thụ xong đầu tiên sẽ được quyền nhận đơn vị công việc tiếp theo.
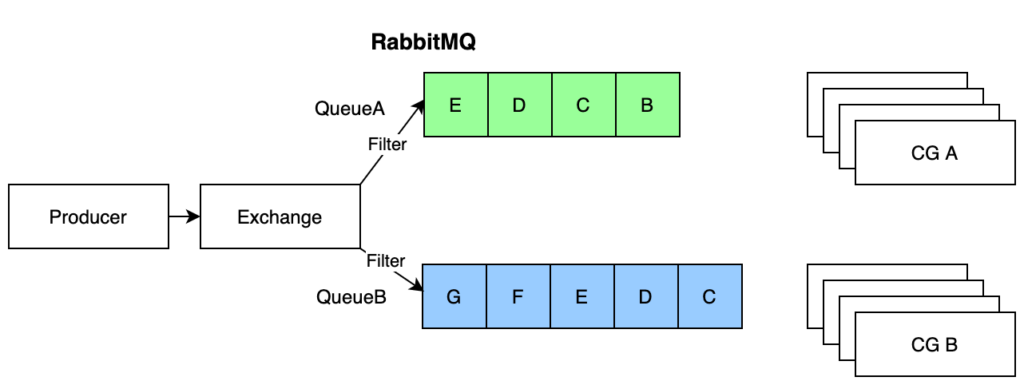
Có thể thiết lập để consumer không đánh dấu rằng công việc đã hoàn thành. Đây là một giải pháp được khuyến khích trong trường hợp các consumer chỉ cần biết có điều gì đó đã xảy ra, hơn và coi mỗi sự kiện như một đơn vị công việc cần phải giải quyết một lần duy nhất.
Thường thì RabbitMQ lưu trữ các event trong bộ nhớ, điều này có thể là một yếu tố hạn chế. Và có nhiều cách để giải quyết vấn đề này. Thiết lập RabbitMQ để có tính nhân bản và tính available cao là một nhiệm vụ dự kiến.
Một vài cân nhắc ở cấp cao
- Replay
- Kafka tốt, nó được thiết kế để lưu tồn dữ liệu, và dữ liệu có thể được phát lại trong suốt vòng đời của Topic
- RabbitMQ không tốt, nó được thiết kế để bỏ quên dữ liệu đi một khi công việc đã được hoàn thành
- Điều hướng
- Kafka không tốt, bất kỳ consumer nào được phép nhận sự kiện từ một topic sẽ nhận được tất cả các sự kiện từng được xuất bản tại Topic đó. Sau đó consumer lựa chọn dữ liệu nào nó cần tiêu thụ
- RabbitMQ tốt, exchange sẽ lựa chọn dữ liệu nào được ghi vào queue và sau đó consumer chỉ nhận được những event đã được ghi vào queue được chỉ định dành cho nó
- FIFO
- Kafka tốt, các Kafka producer có thể ngắm đến một partition cụ thể trong một topic và được đảm bảo FIFO khi sản xuất. Các consumer được đảm bảo tiêu thụ theo thứ tự FIFO trong một partition, ngụ ý rằng chỉ có một consumer hoạt động trên một FIFO partition.
- RabbitMQ không tốt, bởi các RabbitMQ consumer có sự cạnh tranh, quá trình xử lý sự kiện có thể diễn ra theo hướng một sự kiện xảy ra trước, được bắt đầu tiêu thụ trước, nhưng lại được hoàn thành sau.
- Quyền ưu tiên
- Kafka không tồn tại khái niệm consumer ưu tiên.
- Với RabbitMQ, chúng ta có thể chỉ định những event được ưu tiên, và các consumer sẽ ưu tiên tiêu thụ chúng
- Độ trễ
- Kafka ổn, các Kafka consumer bầu chọn với nhau để được lấy event từ broker, độ trễ từ thao tác bầu chọn có thể được giảm xuống nhưng đồng thời cũng làm tăng mức tải
- RabbitMQ tốt hơn, các sự kiện được đẩy tới consumer rảnh rỗi ngay khi chúng được xuất bản
Hai thiết kế chính của hàng đợi
Có hai loại event chính: Queue event và Publish/Subscribe event.
- Queue event:
- Producer có một đơn vị công việc mới cần phải xử lý (thường chỉ một lần)
- Consumer hoạt động, tiêu thụ sự kiện, thông báo cho hệ thống hàng đợi, và công việc được xóa bỏ khỏi hàng đợi
- Publish/Subscribe event:
- Producer xuất bản một event (tiềm năng cho một số công việc phát sinh)
- Các consumer lắng nghe và chọn lọc những gì chúng cho rằng sẽ phát sinh công việc
Một số ứng dụng
- Queue event:
- Bộ đệm đầu vào: nhận sự kiện, duy trì sự kiện trong thời gian tối thiểu, xử lý càng nhanh càng tốt, và thông báo cho bên gửi càng sớm càng tốt. Rất thích hợp xử lý các sự kiện một cách bất đồng bộ
- Niêm cất giữ liệu: đặt ra thời gian chờ xử lý dài hơn, cho phép các consumer có cái nhìn toàn cảnh về các sự kiện theo thời gian
- Nhật ký sự kiện: xếp hàng đợi cho các công việc trong một khoảng thời gian, và sau đó xử lý hàng loạt. Chẳng hạn: bảo trì cuối ngày.
- Publish/Subscribe event:
- Thay đổi trạng thái/cấu hình tại runtime: thông báo cho nhiều ứng dụng về sự thay đổi cấu hình
- Thống kê: chia sẻ trạng thái dịch vụ, SLA…
- Caching: cho phép các dịch vụ khác xây dựng bộ đệm dữ liệu có ý nghĩa dựa trên các event mà chúng quan tâm
Tổng kết
Theo xu hướng của kiến trúc microservice, việc quan tâm tới kiến trúc hướng sự kiện sẽ là một bước đi tất yếu. Bài viết này đã giải thích câu hỏi tại sao. Về các quan điểm ra quyết định lựa chọn giữa Kafka và RabbitMQ, trên đây chỉ là các khía cạnh cấp cao và vẫn còn nhiều chi tiết mức thấp khác còn cần phải bàn tới.